
Compact Forwarding Information
on June 25, 2020The work presented here is performed as part of the joint research project between Oracle, Uppsala University and KTH. Follow the blog series here at inside.java to read more about the JVM research performed at the Oracle Development office in Stockholm.
This is a short description about my work on garbage collection that I did for my master thesis. This work was done in collaboration with Oracle which gave me an opportunity to work with brilliant minds on challenging problems. I want to direct a special shoutout to my mentors at Oracle, Per Lidén and Erik Österlund.
To allow fast allocation in garbage collected environments, a common approach is to use bump pointer allocation. Bump pointer allocation uses a pointer to the first available byte in memory that is monotonically increased as we continue to allocate objects. While this scheme allows fast allocation it comes with the caveat that the free memory must be kept continuous. To keep the free memory continuous, many garbage collectors move objects around in memory to compact them, thereby avoiding fragmentation, which can be seen in the figure below. This is typically handled in a process where all live objects are moved off of a page which is then free’d. This permits clearing a page in O(live) objects, which is typically a small number (relatively speaking) since most newly created object tend to die pretty quickly.
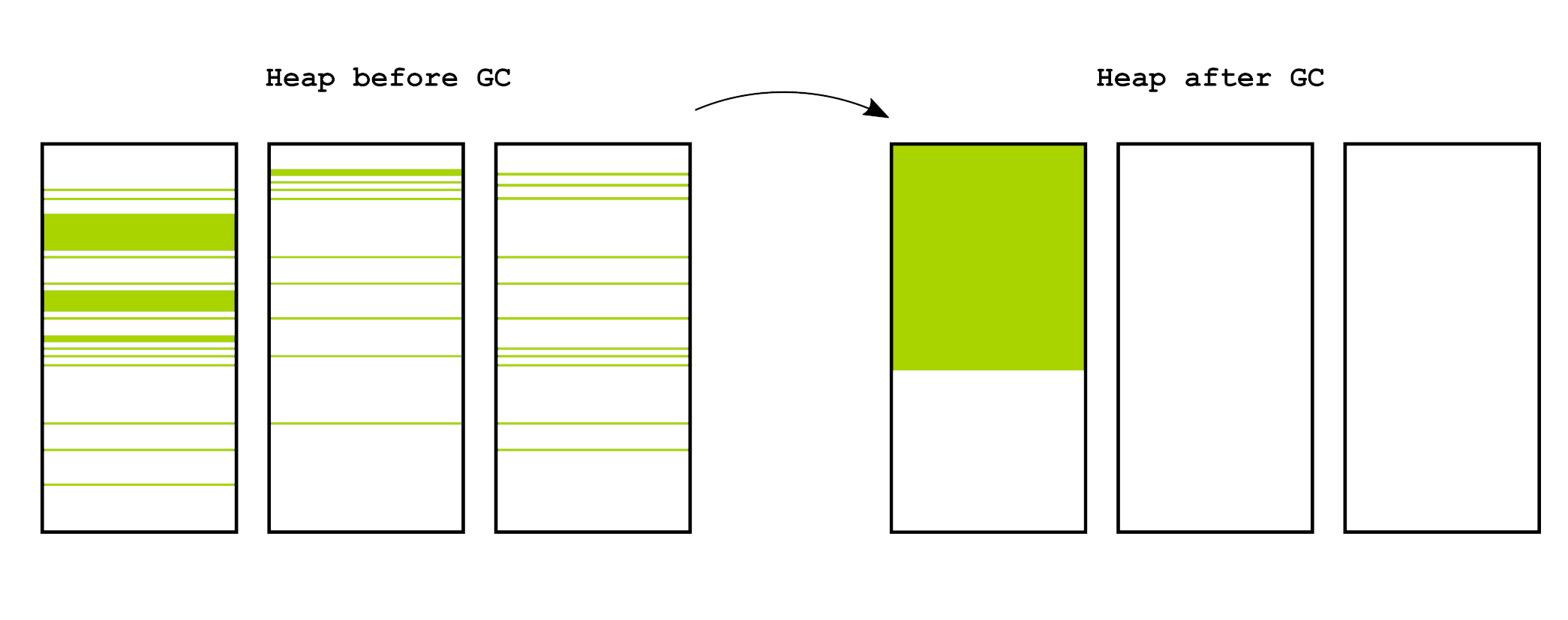
The Z Garbage Collector (ZGC) is a new moving concurrent garbage collector in OpenJDK (the thing that probably runs your Java application) [1, 2]. ZGC moves objects around, to combat memory fragmenation, without stopping the application. This imposes additional overhead on an application in the form of tracking objects’ movements, so that all pointers to them can eventually be updated to the new locations. Usually in GC parlance this is referred to as forwarding information.
ZGC uses an auxiliary forwarding table – optimised for fast look-up, at the cost of additional memory use. This forwarding table is stored outside of the Java heap, referred as off heap-allocation. Any off-heap allocation or keeping old object after moving them is to be considered as memory overhead since it is strictly needed for the JVM and not the actual Java application. ZGC suffers from pathological cases where the size of its forwarding information can become very large, theoretically, as big as the heap itself. If we dimension an application for the pathological case this would be a waste of resources, since the memory usage is usually significantly less. This can make it hard to determine an application’s memory requirements.
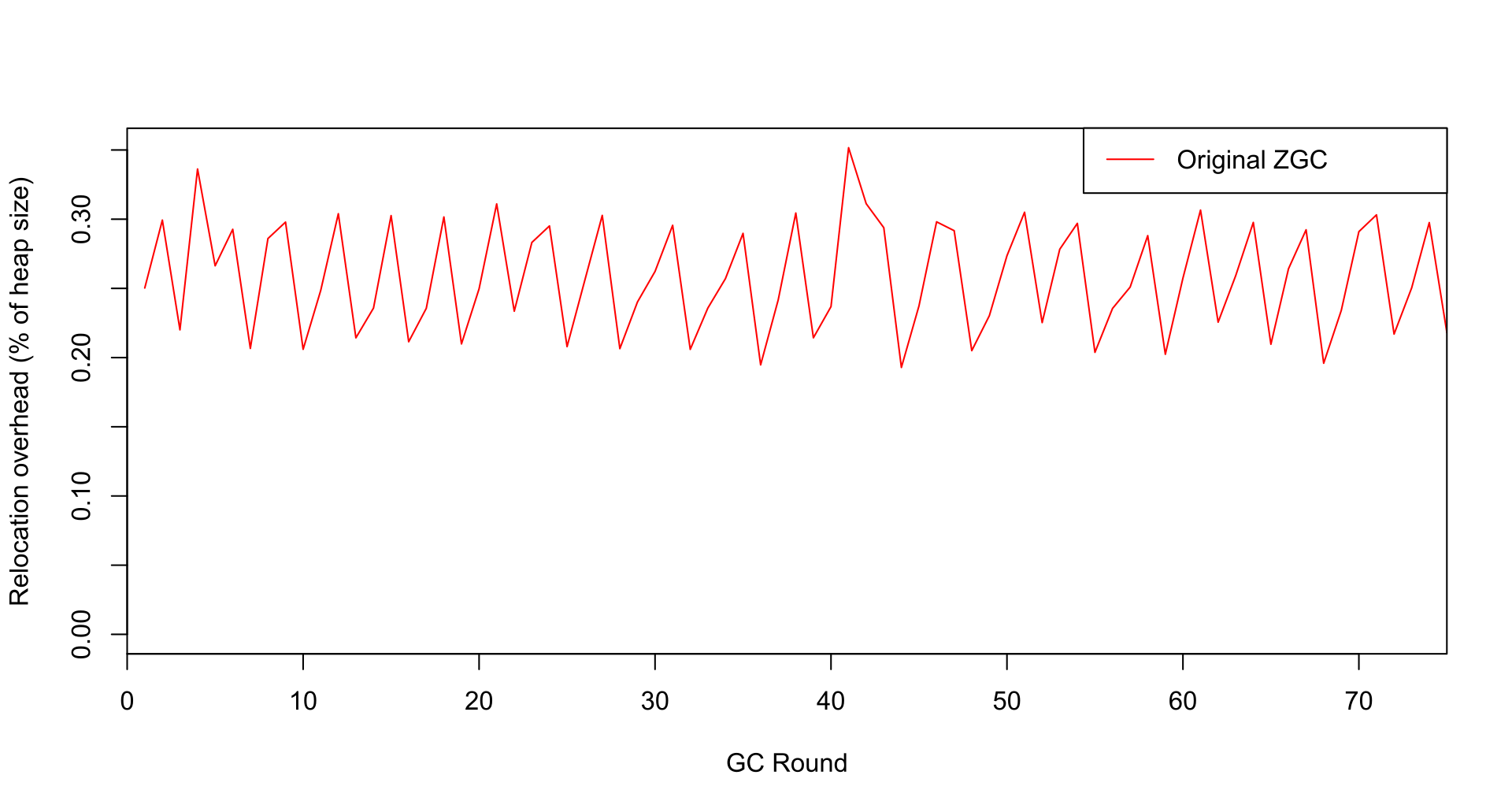
This risk for large memory overhead is not only a theoretical concern, but can be observed in real programs. Below is a plot depicting the memory overhead for an internal benchmark application called BigRamTester at Oracle, which shows 35% memory overhead. The source code for that application can be found in this issue as an attachment.
Storing forwarding information for each relocated object from addresses A (the from-address) to B (the to-address), costs approximately 128 bytes (64 bytes for each from/to-address), can be implemented computationally efficient but at the cost of additional memory overhead (as shown above). As part of my thesis work, we propose a new design for forwarding tables that maps several sparesly populated pages (i.e., with few live objects) onto a single new page in a way that allows the to-address to be calculated using the from-address and liveness information. The design results in a compressed forwarding table that incurs a theoretical worst-case memory overhead of < 3.2%.
In ZGC, there may be contention between application threads and garbage collector threads of relocating objects. The contention results in nondeterministic addresses to which objects are relocated to. The new design requires deterministic addresses so that we can calculate the new address given some set of information. Assume that we have an old page X, whose objects will be relocated to the new page Y. We achieve deterministic addresses, if we copy the objects to Y in the order we encounter them when traversing the live map from the beginning to the end, in ascending order.
The new design divides pages into Q amount of chunks. A chunk holds the amount of preceding living objects before that chunk. To get the size of previously living objects you will use the associated chunk and scan the live map for the addresses who wasn’t covered by the chunk. This allows X to be computed efficiently and allows the old page to be freed as soon as all objects have been relocated, at the cost of some space. An example of dividing a page into chunks is depicted below.
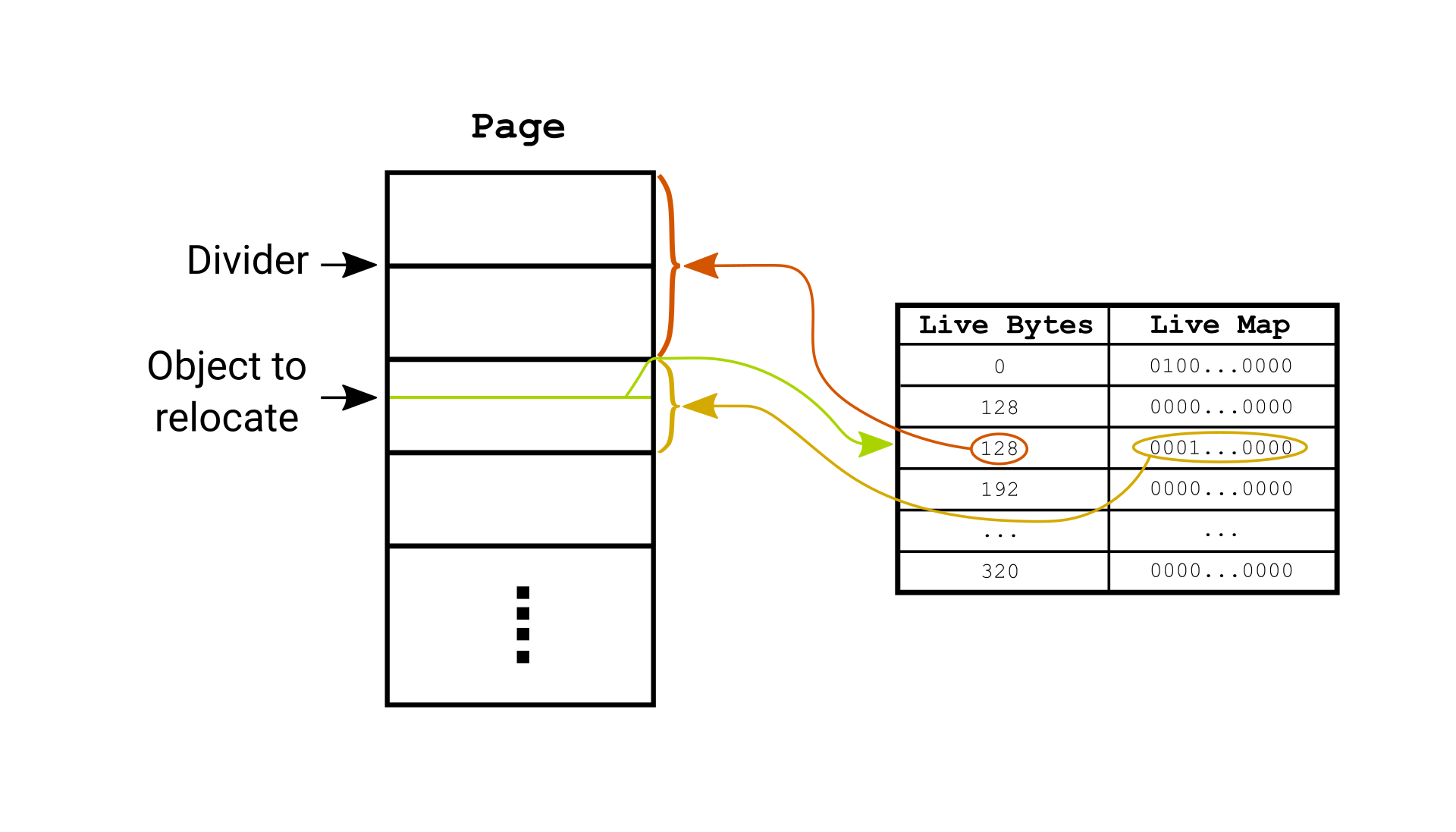
Each page divider corresponds to one chunk’s live map coverage. In the example, an object to be relocated lives on the third page which covered by the third chunk (the green arrow). To find the address we do not have to scan the previous chunks since the live bytes field is describing the amount of live bytes of all preceding chunks (the red arrow). Finding all living objects (and their size) preceding the green object within the chunk, can be found in the live map (the yellow arrow).
This design results in a simple logic in order to calculate the new address, which in pseudocode would be express as:
inline uintptr_t ZCompactForwarding::to_address(uintptr_t from_address) {
uintptr_t to_page_start_address = to_page_start_address(from_address);
uintptr_t live_bytes_before_chunks = live_bytes_before_chunks(from_address)
uintptr_t live_bytes_on_chunks = live_bytes_on_chunks(from_address);
return
to_page_start_address +
live_bytes_before_chunk +
live_bytes_on_chunks;
}
The implementation was shown to have a maximum of < 3.2% memory overhead. I used the DaCapo benchmarks suite and the SPECjbb2015 benchmark to evaluate the impact of the design on execution time, given that forwarding addresses must now be computated, as opposed to looked up. Naturally, we expected some performance degradation. The results from the benchmarking show an statistically significant average performance degradation of approximately 2%, for the new design. Notably, many programs in DaCapo were not effected at all. Two DaCapo programs saw performance improvements at 5.69% and 22.42%, respectively, for the new design.
I haven’t implemented all optimizations on my list (yet). But I’m fairly hopeful that decrease in memory footprint and predictable overhead outweighs the increase in execution time, as incidated by the measurements. This could mean that the work you’d just read about will hopefully find its way into OpenJDK. Only time will tell.
References
[1] Lidén P. CFV: New Project: ZGC; 2017.
[2] Lidén P, Karlsson S. JEP 333: ZGC: A Scalable Low-Latency Garbage Collector.