
Inside Java
News and views from members of the Java team at Oracle
News and views from members of the Java team at Oracle
The work presented here is performed as part of the joint research project between Oracle, Uppsala University, and KTH. Follow the blog series here at inside.java to read more about the JVM research performed at the Oracle Development office in Stockholm.
Hi there!
My name is William Sjöblom. During the latter half of 2020, I wrote my master's thesis at Oracle, concluding my final year of the five-year M.Sc. in Computer Engineering at Linköping University.
In my master's thesis, I investigated additional opportunities for automatic vectorization in the HotSpot C2 compiler, part of the OpenJDK. Specifically, I investigated automatic vectorization of inner-most loops with cross-iteration dependencies, with the initial goal of handling the recurring polynomial hash functions in the Java Class Library. That is, making C2 aware of the data-parallelism in these hash functions to generate performant SIMD code.
To accomplish this, an additional loop optimization pass was added. This new pass extracts a tree-based representation of the loop body data-flow, with nodes representing primitive operations (such as binary operations and array loads). This tree is then pruned according to a set of rewrite rules such that the tree will be pruned down to a single node in case the initial tree corresponds to a pre-defined idiom. In this context, an idiom refers to a known computational kernel for which the compiler has been made aware of more performant SIMD implementation. So, in case the pruning process produces a single node, we simply replace the loop under optimization with our pre-defined SIMD implementation.
In its current state the optimization pass is aware of two separate idioms: reductions and prefix sums. The reduction idiom encompasses a wide range of array reductions (including the previously discussed polynomial hash functions) and uses the recursive doubling technique for its SIMD implementation. The prefix sums idiom, implemented to demonstrate the generality of the technique, encompasses loops computing all running-totals of an array and uses the parallel prefix sum algorithm proposed by Hillis and Steele for its SIMD implementation.
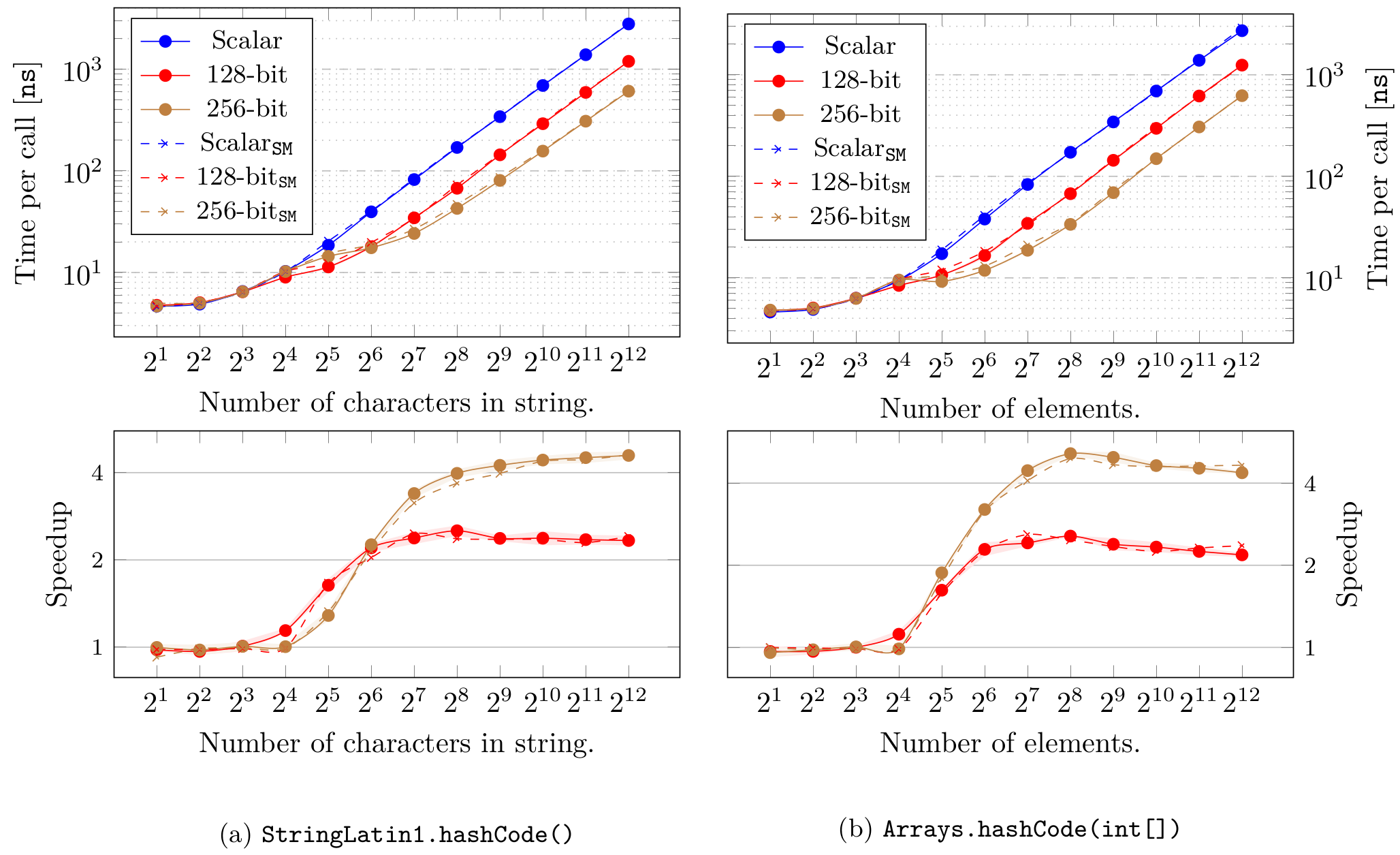
Above are two of the more interesting results from the performance evaluation, containing performance figures for two of the previously mentioned polynomial hash functions. The plots show performance figures for the baseline scalar implementation and our automatically vectorized implementations (using 128-bit and 256-bit vector lengths). As you can see, there is performance to be gained by exploiting the data-parallelism given to us in these methods. Similarly, we observed strongly significant speedups for the prefix sums as well, indicating that vectorization of recurring computational kernels is indeed a worthwhile practice.
I am now at the end of my master's thesis and my education as a whole and would like to thank the JPG team at Oracle for giving me the opportunity to end my time as a student on such a high note, both by letting me work on the magnificent piece of engineering that is HotSpot and by giving me the support I needed in the process. Hopefully, my contributions will someday be merged into the OpenJDK-mainline, so that you too can experience the immense joy of String.hashCode hitting ludicrous speed.