
Inside Java
News and views from members of the Java team at Oracle
News and views from members of the Java team at Oracle
The work presented here is performed as part of the joint research project between Oracle, Uppsala University and KTH. Follow the blog series here at inside.java to read more about the JVM research performed at the Oracle Development office in Stockholm.
My name is Filip Wilén and I wrote my master's thesis at Oracle during autum 2022. This thesis was conducted in collaboration with Oracle’s Stockholm office. I want to share my deepest appreciation to Roberto Castañeda Lozano and the team at Oracle for their experience and guidance throughout this process.
My master thesis performed a throughput evaluation on a proposed optimization called safepoint attached-barriers (SAB), for the OpenJDK Hotspot´s concurrent garbage collector generational ZGC. The main task of my thesis was to answer if the optimization generated any significant throughput benefits, and to find the optimization’s main throughput limitations. This knowledge can then be used to decide if SAB should be implemented in the released version of ZGC. The full thesis can be found here.
The idea behind concurrent memory management is to run application threads and garbage collector threads simultaneously. However, this might result in pointers referencing the wrong memory field, as the application and the garbage collector access the Java heap at the same time. To address this problem, the Generational ZGC uses barriers for each store and load operation that check and, if necessary, restore the pointer’s reference to the correct address. Unfortunately these barriers introduce an overhead, but in theory, the barriers are only needed if the heap has been rearranged. Therefore, a JIT compiler optimization called “safepoint-attached barriers” has been suggested to reduce the number of barriers in sections of the program were heap stability can be assured. As a simplified example, SAB assures heap integrity and removes barriers if the algorithm can assure that a memory field with removed barrier has been checked by another barrier previously. This results in the removal of unnecessary barriers, which results in an increase in throughput.
The optimization was evaluated on the SPECjvm2008 [1] and DaCapo2009 version 9.12-bach-MR1 [2] benchmark suites. Figure 1 shows the normalized execution time for benchmarks in the DaCapo benchmark suite. From SPECjvm and DaCapo, only 4 / 21 benchmark showed a statistically significant median throughput improvement. The benchmark fop-default had the best improvement with a reduction in execution time of about 1 %. Futhurmore, the other 17 / 21 benchmarks showed no significant regressions. This means that SAB does not cause any obvious throughput limitation, but only accives a statistically significant throughput increase for some specific benchmarks.
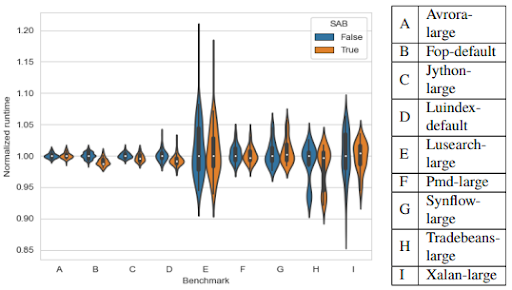
*Figure 1: Violin plots of the relative throughput results with SAB enabled and disabled on different DaCapo benchmarks. Each benchmark was executed 50 times, the measured runtime for each benchmark ranges between 1-10 s.
The throughput benefit of the SAB Optimization is dependent on number of barriers elided. Barriers can be counted both statically and dynamically. Static counting means that we count the barriers each time they occur in the code, while dynamic counting means that barriers are counted every time they are reached during runtime.
To count barriers, an instrumentation tool has to be implemented into the JVM. With this tool it can be determined that generally 10 - 20% of static barriers can be removed for most benchmarks. However, the number of dynamic barriers removed is often significantly lower, suggesting an existing limitation in removing barriers from repeated code. Figure 2 shows the runtime reduction in correlation with the percentage of median dynamic barriers removed from the DaCapo and SPECjvm benchmark suites. From this scatterplot, there seems to be a correlation between runtime reduction and dynamic barriers removed.
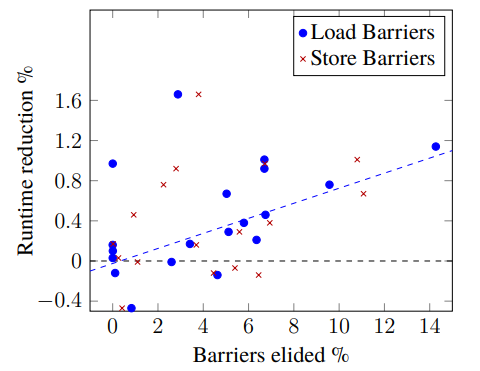
Figure 2: Correlation between dynamic barriers removed and improved throughput from DaCapo and SPEC benchmarks. No barrier count differed more than 15%.
By further evaluation of the dynamic barrier elimination rates inside the DaCapo benchmark suite, two main SAB limitations can be found. The limitation in barrier removals in repeated code segments is caused by inlining and the static analysis done by the JIT compiler.
Inlining means that a method call is replaced with the body of the call. During compilation all barriers tracked reside within the same compilation unit, meaning that a method is picked (root method) and a number of further method calls are inlined into this method. These are all barriers that can be tracked in the current compilation unit. This results in a limit on how many, and which barriers can be removed as the JIT compiler has inner limits on how much code that can be inlined. For SAB this limitation results in less barriers removed overall, but especially for repeated code segments.
With these limitations in mind, a simple solution to improve barrier elisions might be to increase the inlining limits set by the compiler. Figure 3 tests this on the DaCapo benchmark suite, where each data point is the same benchmark with a different inlining limit. The limits are increased with Method bytecode size (max bytecode size for methods to be inlined) and Inline max byte size (max size of methods with inlined methods). However, as seen in Figure 3, this does not seem to be an obvious solution as most benchmarks do not get a significant increase in number of barriers dynamically elided. But on the contrary, the luindex-default benchmark shows that it might exist a benefit in enhancing the inlining decision.
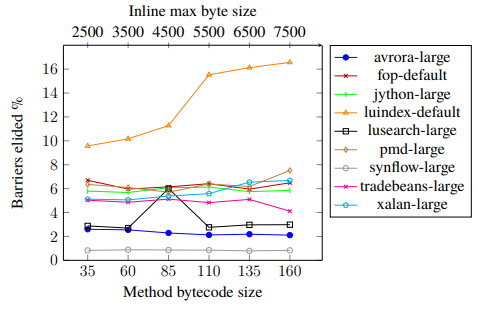
Figure 3: SAB load barriers elided in DaCapo benchmarks dependent on inlining limit. Each data point is the median count of 5 runs where the deviation in barriers elided was less than 10%.
The other Limitation involves the static analysis done by the JIT compiler to remove barriers. This limitation is illustrated by Listing 1, where the compiler only sees a single barrier even if it is executed multiple times. This results in a significant number of barriers unnecessarily executed.
//Limitation
while(i < 100) {
//Load barrier cannot be removed
obj load = obj.l;
i++;
}
Listing 1: The Load barrier on line 4 cannot be removed even when the barrier is executed multiple times.
This can be solved with the help of loop peeling, shown in Listing 2. By moving one iteration outside the main loop, the barrier inside the loop can be elided resulting in a possibility to remove multiple dynamic barriers.
// Solution with loop peeling
obj load = obj.l;
i++;
while(i < 100) {
//Load barrier removed!
obj load = obj.l;
i++;
}
Listing 2: The solution to the problem in Listing 1 is to use loop peeling, this results in one iteration of the loop being executed before the main body.
For most benchmarks, SAB did not generate an increase in throughput, but when the increase was statistically significant, the increase was < 1%. However, my thesis shows that there exists possible throughput improvements to the algorithm, in the form loop peeling and enhanced inlining decisions. Hopefully these new insights will help in deciding if safepoint-attached barriers should be implemented in the released version of ZGC.
[1] Specjvm® 2008,” Standard Performance Evaluation Corporation (SPEC), Aug 2017. [Online]. Available: https://www.spec.org/jvm2008/
[2] M. Blackburn et al., “The DaCapo benchmarks: Java benchmarking development and analysis,” in OOPSLA ’06: Proceedings of the 21st annual ACM SIGPLAN conference on Object-Oriented Programing, Systems, Languages, and Applications. New York, NY, USA: ACM Press, Oct. 2006. doi: https://doi.acm.org/10.1145/1167473.1167488 pp. 169–190.