
Inside Java
News and views from members of the Java team at Oracle
News and views from members of the Java team at Oracle
Generative AI, particularly Large Language Models (LLMs), has gained significant attention for its ability to create new content and enhance user experience through natural language processing, making it a priority for businesses looking to enrich their applications with intelligent features. As artificial intelligence (AI) becomes a driving force behind technological innovation, the Java ecosystem is rapidly evolving to meet the demand for AI-powered solutions. Several AI frameworks and libraries became available, some open-sourced, thus stimulating developers to integrate AI-driven functionality. Furthermore, enterprise-level solutions such as Oracle’s Generative AI are enhancing the AI capabilities available for Java applications in cloud-based environments.
This article looks at prominent libraries and frameworks for embedding generative AI capabilities into Java applications, such as LangChain4j, Spring AI, and Jlama, as well as enterprise-level solutions like Oracle's Generative AI. With this knowledge, we will build a conversational chatbot leveraging the Oracle Generative AI service and its Java SDK and enhance its accuracy by further integrating LangChain4j capabilities.

LangChain4j is a Java library designed to simplify the integration of Large Language Models (LLMs) into Java applications. The project began development in early 2023, amid the growing excitement surrounding ChatGPT. The creators of LangChain4j noticed a lack of Java alternatives to the growing number of Python and JavaScript LLM libraries and frameworks at the time. This gap in the Java ecosystem prompted them to develop LangChain4j as a solution.
LangChain4j has quickly gained traction and recognition in the Java community within a year and a half of its inception, especially among developers working on LLM-powered applications. The library is under active development, with new features and integrations being added regularly.
LangChain4j offers several key features that make it a powerful library for integrating Large Language Models (LLMs) into Java applications. It provides a Unified API for accessing various LLM providers, models and embedding stores, allowing developers to easily switch between different LLM models and embedding stores without rewriting code. It also offers a wide range of tools and abstractions specifically designed for working with LLMs.
Its unified API enables integration with a large number of LLM providers and their models, including OpenAI's GPT-3.5 and GPT-4 series models, Google's Gemini, Anthropic's Claude, Cohere models, local models, and various open-source models hosted on Hugging Face. It also supports a growing number of embedding models and embedding vector stores.
LangChain4j's comprehensive toolbox includes Prompt Templates which facilitate the creation of dynamic prompts by defining a prompt structure allowing certain values to be filled at runtime. The library offers Chat Memory Management tools that enable storing and retrieving user interaction history, which is essential for creating conversational agents. Tools in the API allow invoking functions as well as execution of the dynamically generated code by language models. LangChain4j also provides tools for Retrieval-Augmented Generation (RAG), including document loaders, splitters, and retrieval mechanisms. Moreover, it offers AI Services (high-level API) that abstracts away the complexity of working with LLMs, allowing developers to interact with language models through simple Java interfaces.
LangChain4j supports integration with text and image models, enabling more versatile AI applications to be developed. It also integrates well with widespread Java frameworks like Spring Boot and Quarkus, making it easier to incorporate into existing Java projects.

Spring AI is another popular AI integration Java framework. It is an extension of the Spring ecosystem, specifically designed to help connect enterprise data and APIs with AI models. It supports all major AI model providers and offers API support across those providers. It also supports vector databases and model abstraction, which simplifies switching between different AI models. Its API allows models to request the invocation of client-side tools and functions, enabling the model to perform tasks dynamically. Spring AI integrates seamlessly with existing Spring applications, making it a perfect fit for enterprise environments that already rely on Spring's ecosystem.

Jlama offers a native LLM inference engine for Java. If you want to run large language models locally and efficiently within a Java environment, Jlama seems the ideal solution. Jlama is built entirely in Java, utilizing Java libraries and APIs for all LLM operations. It facilitates model execution locally within the Java Virtual Machine (JVM). This eliminates the need for remote APIs or cloud services for inference, making Jlama suitable for use cases that require data privacy, low latency, or offline capabilities. It utilizes the incubated Vector API for faster inference, requiring Java 20 or later. In addition, it supports quantized models, significantly reducing local memory usage and inference time.
Oracle Generative AI is a managed Oracle Cloud Infrastructure (OCI) service that provides a set of customizable large language models (LLMs) covering a wide range of use cases, including chat, text generation, summarization, and creating text embeddings. Moreover, the offering includes an SDK for Java for integrating generative AI models into Java applications. Please visit here for steps to access and install the SDK for Java.
Note that an Oracle Cloud Infrastructure account is needed to access any OCI service. Please follow this link to find out more on the current free tier and get your own account.
Moreover, OCI Generative AI service offers a number of large language models for generic chat service.

Figure 1: OCI Chat Models
Now that we know what mainstream options exist to work with Java and generative AI, let's enhance our learning by building a simple program that creates a command-line chatbot backed up by an LLM model from the OCI Generative AI Service.
We will develop a chatbot utilizing the OCI SDK for Java, enabling users to engage in natural language conversations with it.
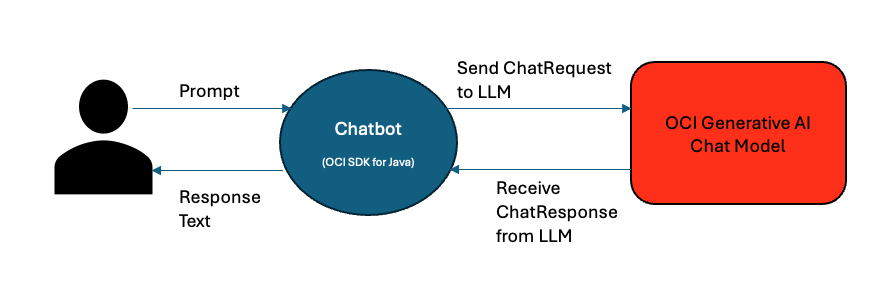
Figure 2: Chatbot using OCI SDK for Java
For this example, we will start with creating a Java Maven project. You may leverage your favorite IDE to generate a basic pom.xml and a default directory structure for a Maven project with the source folder defined. The pom.xml file is a single configuration file that contains the majority of information required to build the project.
Next, we will customize the pom file with the following dependencies in the pom.xml file to access the OCI SDK for Java.
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-common</artifactId>
<version>3.55.1</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-common-httpclient-jersey</artifactId>
<version>3.55.1</version>
</dependency>
<dependency>
<groupId>com.oracle.oci.sdk</groupId>
<artifactId>oci-java-sdk-generativeaiinference</artifactId>
<version>3.55.1</version>
</dependency>
The oci-java-sdk-common library is a core module of the OCI Java SDK. It provides essential utilities, shared configurations, and foundational components for Java applications to interact effectively with OCI services. The oci-java-sdk-common-httpclient-jersey module provides functionality focusing on HTTP client interactions using the Jersey framework. Finally, the oci-java-sdk-generativeaiinference module supports interaction with the OCI Generative AI service.
To use the OCI SDK, we first need to authenticate ourselves. The easiest way to achieve that is via Oracle Cloud Infrastructure (OCI) Command Line Interface (CLI), oci, whose installation instructions are available here. Next, follow the instructions to set up a configuration file. Going through these steps will result in creating a config file whose location depends on your operating system; for example, for Unix-compatible environments, this is available at ~/.oci/config.
Once we have obtained the config file, we can provide that location to our chatbot application and set up its OCI access, including generative AI endpoint, configuration details, and compartment ID. You can further use config file location and setup a OCIGenAIEnv class, like the one below, to hold environment-specific configuration settings for the Oracle Cloud Infrastructure (OCI) Generative AI service.
public class OCIGenAIEnv {
// The OCI Generative AI service is available in several regions.
// https://docs.oracle.com/en-us/iaas/Content/generative-ai/overview.htm#regions
// Here, we use the Generative AI service endpoint in Chicago region.
private static final String ENDPOINT = "https://inference.generativeai.us-chicago-1.oci.oraclecloud.com";
// location of the OCI configuration file
private static final String CONFIG_LOCATION = "~/.oci/config";
// profile name within the OCI configuration file to use
private static final String CONFIG_PROFILE = "DEFAULT";
// unique identifier of the compartment that has the policies granting
// permissions for using the Generative AI Service. See how to set policies:
// https://docs.oracle.com/en-us/iaas/Content/generative-ai/iam-policies.htm
private static final String COMPARTMENT_ID = "ocid1.compartment.oc1..xxx";
}To keep the Compartment ID secure, set the COMPARTMENT_ID as an environment variable instead of hardcoding it, and access it using
System.getenv("COMPARTMENT_ID").
Next, we ensure secure communications with OCI services by instantiating AuthenticationDetailsProvider with OCIGenAIEnv constants. We will then use this provider to create a GenerativeAiInferenceClient, which facilitates interaction with an OCI language model.
// read configuration details from the config file and create an AuthenticationDetailsProvider
ConfigFileReader.ConfigFile configFile;
AuthenticationDetailsProvider provider;
try {
configFile = ConfigFileReader.parse(OCIGenAIEnv.getConfigLocation(), OCIGenAIEnv.getConfigProfile());
provider = new ConfigFileAuthenticationDetailsProvider(configFile);
} catch (IOException e) {
throw new RuntimeException(e);
}
// Set up Generative AI inference client with credentials and endpoint
ClientConfiguration clientConfiguration =
ClientConfiguration.builder()
.readTimeoutMillis(240000)
.build();
GenerativeAiInferenceClient generativeAiInferenceClient =
GenerativeAiInferenceClient.builder()
.configuration(clientConfiguration)
.endpoint(ENDPOINT)
.build(provider);To generate a response to a user's request, the chatbot needs to know how to invoke the Generative AI models. To achieve this, the SDK offers a response serving mode representation via the ServingMode class that you can further configure with an OCI chat model. For this example, I used the meta.llama-3.1-405b-instruct model and defined its invocation through OnDemandServingMode, which represents a mode where Generative AI models are invoked on-demand, without requiring pre-deployment or continuous hosting of the model.
ServingMode chatServingmode = OnDemandServingMode.builder()
.modelId("meta.llama-3.1-405b-instruct")
.build();Following this, we can prepare a ChatRequest, send it to the LLM model using the instance of GenerativeAiInferenceClient created above and then receive a generated response from it.
// Send the given prompt to the LLM to generate a response.
public ChatResponse generateResponse(String prompt) {
// create ChatContent and UserMessage using the given prompt string
ChatContent content = TextContent.builder()
.text(prompt)
.build();
List<ChatContent> contents = List.of(content);
Message message = UserMessage.builder()
.content(contents)
.build();
// put the message into a List
List<Message> messages = List.of(message);
// create a GenericChatRequest including the current message, and the
// parameters for the LLM model
GenericChatRequest genericChatRequest = GenericChatRequest.builder()
.messages(messages)
.maxTokens(1000)
.numGenerations(1)
.frequencyPenalty(0.0)
.topP(1.0)
.topK(1)
.temperature(0.75)
.isStream(false)
.build();
// create ChatDetails and ChatRequest providing it with the compartment ID
// and the parameters for the LLM model
ChatDetails details = ChatDetails.builder()
.chatRequest(genericChatRequest)
.compartmentId(OCIGenAIEnv.getCompartmentID())
.servingMode(chatServingMode)
.build();
ChatRequest request = ChatRequest.builder()
.chatDetails(details)
.build();
// send chat request to the AI inference client
return generativeAiInferenceClient.chat(request);
}The response text is embedded in the ChatResponse object returned by generativeAiInferenceClient.chat(). To extract text from the ChatResponse you may try the snippet shown below.
public String extractResponseText(ChatResponse chatResponse) {
// get BaseChatResponse from ChatResponse
BaseChatResponse bcr = chatResponse
.getChatResult()
.getChatResponse();
// extract text from the GenericChatResponse response type
// GenericChatResponse represents response from llama models
if (bcr instanceof GenericChatResponse resp) {
List<ChatChoice> choices = resp.getChoices();
List<ChatContent> contents = choices.get(choices.size() - 1)
.getMessage()
.getContent();
ChatContent content = contents.get(contents.size() - 1);
if (content instanceof TextContent textContent) {
return textContent.getText();
}
}
throw new RuntimeException("Unexpected ChatResponse");
}Now, let's invoke the above methods with a prompt about Java memory leaks.
String prompt = "How do I troubleshoot memory leaks?";
ChatResponse response = generateResponse(prompt);
System.out.println(extractResponseText(response));To validate our work, we should have the assistant up and running:
Use your IDE's capabilities to manage the lifecycle of a Maven project or quickly run mvn verify in a terminal window. This action will create the troubleshoot-assist-1.0.0.jar file inside the target directory.
Launch the application via mvn exec:java -Dexec.mainClass=JavaTroubleshootingAssistant.
Our chatbot replies with the following:
The age-old problem of memory leaks! Troubleshooting memory leaks can be a challenging and time-consuming process, but with the right tools and techniques, you can identify and fix them. Here's a step-by-step guide to help you troubleshoot memory leaks:
**Preparation**
1. **Understand the symptoms**: Identify the symptoms of the memory leak, such as:
* Increasing memory usage over time
* Performance degradation
* Crashes or errors due to out-of-memory conditions
2. **Gather information**: Collect relevant data about the system, application, and environment, including:
* Operating system and version
* Application version and architecture (32-bit or 64-bit)
* Memory configuration (RAM, virtual memory, and paging file settings)
3. **Choose the right tools**: Select the tools you'll use to troubleshoot the memory leak, such as:
* Memory profiling tools (e.g., Visual Studio, Valgrind, or AddressSanitizer)
* System monitoring tools (e.g., Task Manager, Performance Monitor, or top)
* Debugging tools (e.g., gdb, WinDbg, or Visual Studio Debugger)
**Step 1: Monitor System Resources**
1. **Track memory usage**: Use system monitoring tools to track memory usage over time, including:
* Total memory usage
* Memory usage by process or application
* Memory allocation and deallocation patterns
2. **Identify memory-intensive processes**: Determine which processes or applications are consuming the most memory.
**Step 2: Analyze Memory Allocations**
1. **Use memory profiling tools**: Run memory profiling tools to analyze memory allocations and identify potential leaks.
2. **Collect memory dumps**: Collect memory dumps or snapshots to analyze memory allocation patterns.
3. **Analyze memory allocation patterns**: Look for patterns of memory allocation and deallocation, such as:
* Memory allocated but not released
* Memory allocated repeatedly without being released
* Large memory allocations
**Step 3: Inspect Code and Data Structures**
1. **Review code**: Inspect the code for potential memory leaks, focusing on areas with high memory allocation and deallocation activity.
2. **Check data structures**: Verify that data structures, such as arrays, lists, or trees, are properly managed and released.
3. **Look for circular references**: Identify potential circular references that could prevent memory from being released.
**Step 4: Debug and Test**
1. **Use debugging tools**: Use debugging tools to step through the code, inspect variables, and identify potential issues.
2. **Test hypotheses**: Test hypotheses about the cause of the memory leak by modifying the code or data structures.
3. **Verify fixes**: Verify that fixes or changes resolve the memory leak.
**Additional Tips**
1. **Test under various conditions**: Test the application under different conditions, such as varying loads, inputs, or environments.
2. **Use automated testing**: Use automated testing tools to simulate user interactions and identify potential memory leaks.
3. **Monitor memory usage regularly**: Regularly monitor memory usage to detect potential memory leaks early.
By following these steps and using the right tools, you'll be well-equipped to troubleshoot and fix memory leaks in your application. Happy debugging!
Because we didn't instruct the model on which context to focus on, this response is in no way specific to Java or JVM memory troubleshooting.
What if we want the LLM responses to be specific to Java and JVM troubleshooting? Let's explore how we can achieve that in the next section.
As is often highlighted, LLMs can hallucinate and generate inaccurate or absurd responses or responses that are not specific to the domain we are interested in. However, several techniques can enhance LLMs' accuracy and ground their outputs in factual information. Retrieval Augmented Generation, commonly known as RAG, is one of the most popular and effective techniques.
This section covers enhancing the context-awareness of the previous Java Troubleshooting Assistant to answer our Java troubleshooting-related questions by implementing a RAG technique with LangChain4j. The assistant will generate its responses based on the information available in the Java Platform, Standard Edition, Troubleshooting Guide.
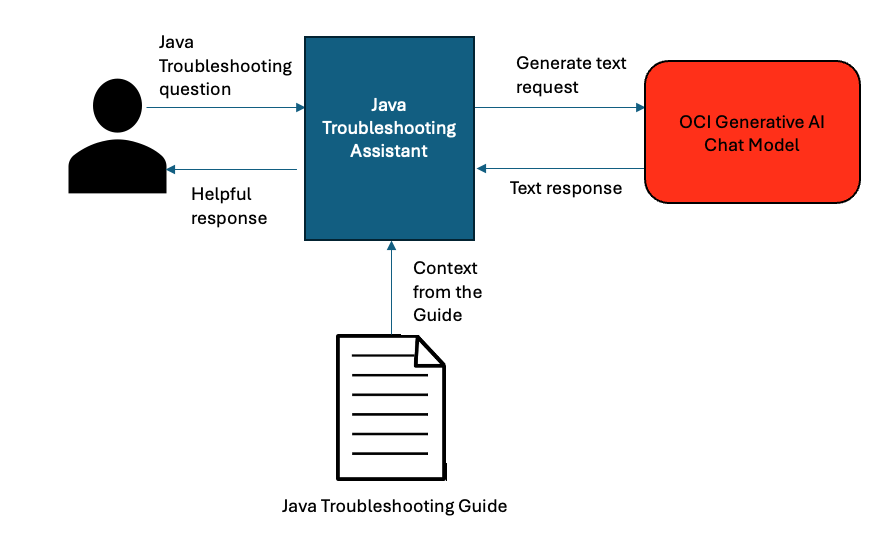
Figure 3: Java Troubleshooting Assistant
Let's start with including the following LangChain4j dependencies in your pom.xml project file.
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.36.2</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>0.36.2</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-chroma</artifactId>
<version>0.36.2</version>
</dependency>
To further improve this assistant, we will create embeddings for our document, store them in a vector database, add the ability to retrieve context from the database for our prompts, and augment the prompts with the context. Moreover, we will add chat memory to remember the history of messages in our conversation.
1. Create Embeddings using an Embedding Model
The first step is to create a knowledge-base from the information available in the troubleshooting guide (e.g. Java Troubleshooting Guide). For that, we need to parse, load the document as pdf file, and split it into reasonably sized chunks:
FileSystemDocumentLoader from the LangChain4j module can help us load pdf files,
ApachePdfBoxDocumentParser can parse text from pdfs.
DocumentSplitter can split the loaded documents into TextSegment chunks, which we pass to the embedding model for generating embeddings, as shown below.
DocumentSplitter documentSplitter = DocumentSplitters.recursive(
800, // Maximum chunk size in tokens
40, // Overlap between chunks
null // Default separator
);
public List<TextSegment> chunkPDFFiles(String filePath) {
List<Document> documents = null;
try {
// Load all *.pdf documents from the given directory
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:*.pdf");
documents = FileSystemDocumentLoader.loadDocuments(
filePath,
pathMatcher,
new ApachePdfBoxDocumentParser());
} catch (Exception e) {
e.printStackTrace();
}
// Split documents into TextSegments and add them to a List
return documents.stream().flatMap(d -> documentSplitter.split(d).stream()).toList();
}Next, we should convert the text from our knowledge document(s) to embeddings, which are vectors of floats representing the meaning of the text in numerical format.
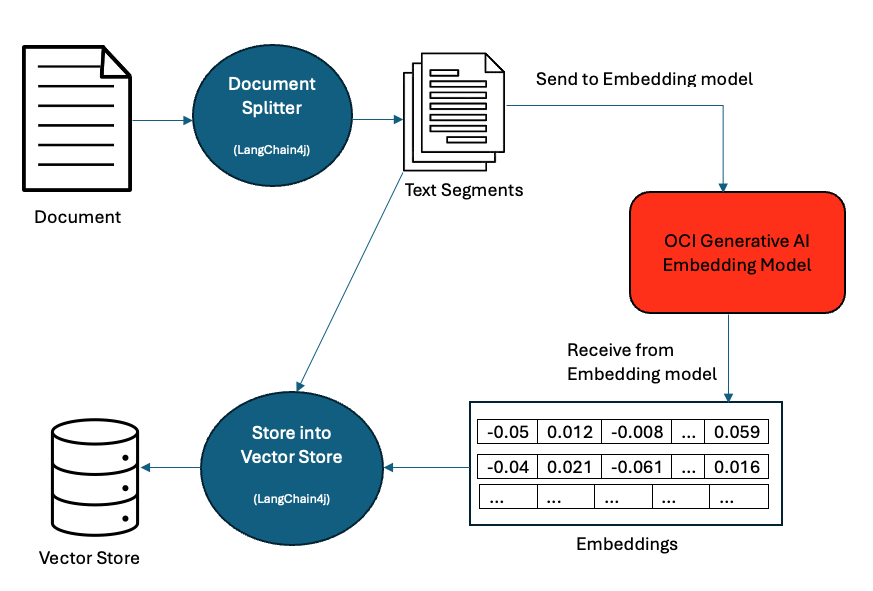
Figure 4: Embeddings and Vector Store
We will use the cohere.embed-english-v3.0 embedding model to create these embeddings, which is available in the OCI Generative AI service.
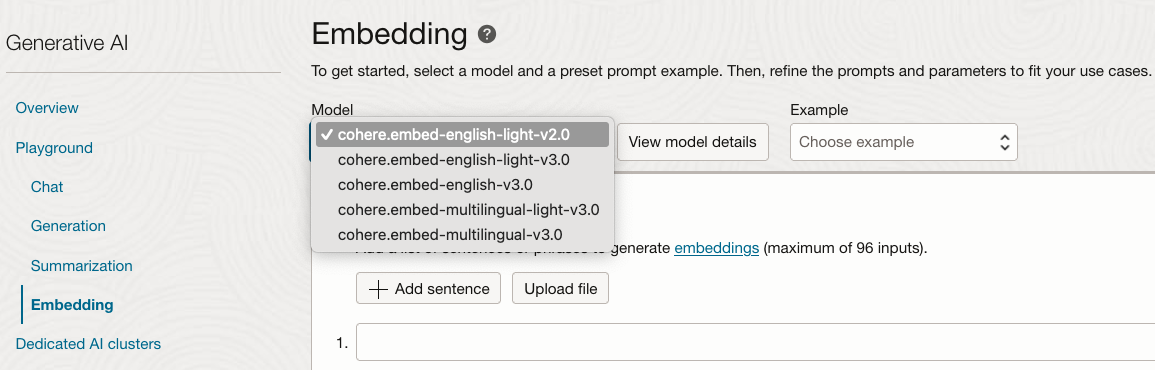
Figure 5: OCI Embedding Models
Next, we will create a new ServingMode to use the embedding model.
// Create a ServingMode specifying the embedding model to be used
ServingMode embeddingServingMode = OnDemandServingMode.builder()
.modelId("cohere.embed-english-v3.0")
.build();We can then send text to this model and get back a vector embedding as a response.
public Embedding embedContent(String content) {
List<String> inputs = Collections.singletonList(content);
// Build embed text details and request from the input string
// use the embedding model as the serving mode
EmbedTextDetails embedTextDetails = EmbedTextDetails.builder()
.servingMode(embeddingServingMode)
.compartmentId(OCIGenAIEnv.getCompartmentID())
.inputs(inputs)
.truncate(EmbedTextDetails.Truncate.None)
.build();
EmbedTextRequest embedTextRequest = EmbedTextRequest.builder().embedTextDetails(embedTextDetails).build();
// send embed text request to the AI inference client
EmbedTextResponse embedTextResponse = generativeAiInferenceClient.embedText(embedTextRequest);
// extract embeddings from the embed text response
List<Float> embeddings = embedTextResponse.getEmbedTextResult().getEmbeddings().get(0);
// put the embeddings in a float[]
int len = embeddings.size();
float[] embeddingsVector = new float[len];
for (int i = 0; i < len; i++) {
embeddingsVector[i] = embeddings.get(i);
}
// return Embedding of LangChain4j that wraps a float[]
return new Embedding(embeddingsVector);
}
public List<Embedding> createEmbeddings(List<TextSegment> segments) {
return segments.stream().map(s -> embModel.embedContent(s.text())).toList();
}2. Embedding Store
Once we have created embeddings for our document, these need to be stored in a database, often referred to as Embedding or Vector Store. We will use ChromaDB embedding store for our example, but be aware that LangChain4j supports a wide range of Embedding Stores.
Start by using docker to pull the chromadb docker image, then run the image to make an instance of chromadb available at a specific port.
docker pull chromadb/chroma
docker run -p 8000:8000 chromadb/chroma
After we have the vector database running and listening at http://localhost:8000, we can now store the embeddings of our document there. Let's first create an instance of EmbeddingStore accessing this vector store.
ChromaEmbeddingStore embeddingStore = ChromaEmbeddingStore.builder()
.baseUrl("http://localhost:8000")
.collectionName("Java-collection")
.build();Then, invoke embeddingStore.addAll() to add the generated embeddings into the store.
public void storeEmbeddings(List<Embedding> embeddings, List<TextSegment> segments) {
embeddingStore.addAll(embeddings, segments);
}Finally, put all the pieces together: chunk the pdf file, create embeddings and then store them in the vector store.
public void createVectorStore(String filePath) {
List<TextSegment> segments = chunkPDFFiles(filePath);
List<Embedding> embeddings = createEmbeddings(segments);
storeEmbeddings(embeddings, segments);
}3. Retrieve and Augment Prompts
This step explains how to obtain relevant answers to users' queries by retrieving information from the store and augmenting the prompts with the retrieved context before sending them to LLM for response generation.
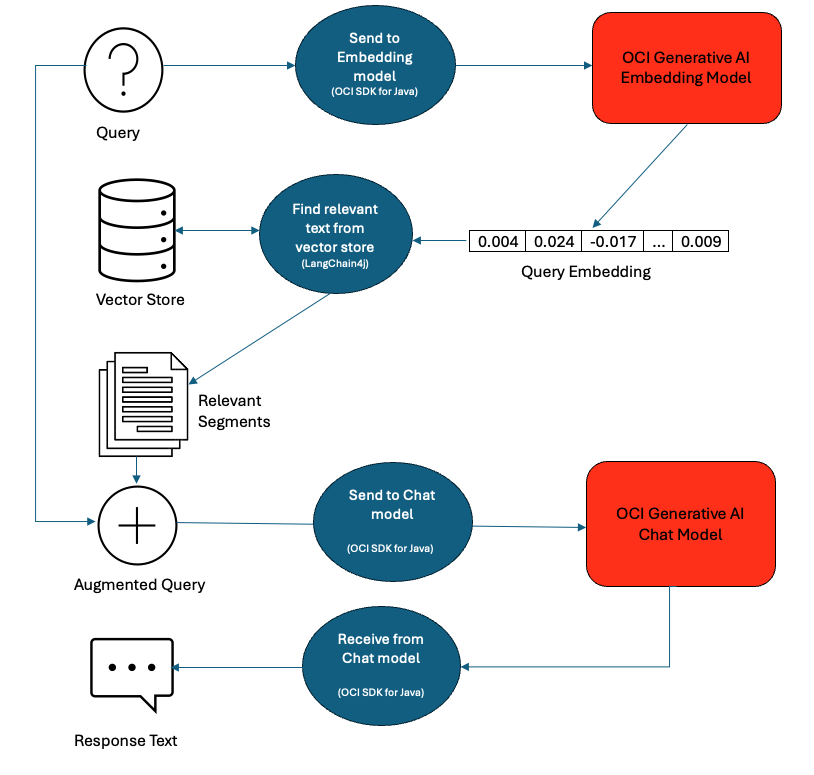
Figure 6: RAG implementation with LangChain4j
Let's use the same question as we had in the previous section:
String question = "How do I troubleshoot memory leaks?";To retrieve context relevant to this question from the knowledge-base, we need to perform a semantic search in the vector store. For this, we first convert this question string to embeddings using the embedContent() method we wrote above.
Embedding queryEmbedding = embedContent(question);Next, we perform a similarity search to extract relevant pieces of text from our knowledge database and chain them together. With PromptTemplate, we combine the original question and the retrieved context to construct a new prompt.
// Find relevant embeddings in embedding store by semantic similarity
int maxResults = 10;
double minScore = 0.7;
List<EmbeddingMatch<TextSegment>> relevantEmbeddings
= embeddingStore.findRelevant(queryEmbedding, maxResults, minScore);
String context = relevantEmbeddings.stream()
.map(match -> match.embedded().text())
.collect(joining("\n\n"));
PromptTemplate template = PromptTemplate.from("""
You are a Java Troubleshooting Assistant. Answer the question in the context of Java or HotSpot JVM.
Always ask if the user would like to know more about the topic. Do not add signature at the end of the answer.
Use only the following pieces of context to answer the question at the end.
Context: {{context}}
Question: {{question}}
Helpful Answer:
""");
// add the question and the retrieved context to the prompt template
Map<String, Object> variables = Map.of(
"question", question,
"context", context
);
Prompt prompt = template.apply(variables);We will send this augmented prompt to the LLM and get a response rooted in information from the troubleshooting guide.
String query = prompt.text();
response = chatModel.generateResponse(query);
System.out.println(extractText(response));Below you can see an example response that uses the augmented prompt:
To troubleshoot memory leaks in Java applications, you can follow these steps:
1. **Enable Options and Flags for JVM Troubleshooting**: Update the Java Runtime and enable options and flags for JVM troubleshooting to collect useful data.
2. **Gather Relevant Data**: Collect diagnostic data such as heap histograms, garbage collection logs, and Java Flight Recordings to analyze memory usage.
3. **Analyze Heap Histograms**: Examine heap histograms to quickly narrow down memory leaks.
4. **Use Heap Dump Analysis Tools**: Utilize tools like Eclipse Memory Analyzer Tool (MAT) or YourKit to analyze heap dumps.
5. **Analyze Java Flight Recordings**: Use JDK Mission Control (JMC) to analyze Java Flight Recordings and identify leaking objects.
6. **Monitor Memory Usage**: Use JConsole and JDK Mission Control to monitor memory usage and live sets.
7. **Detect Native Memory Leaks**: Use Native Memory Tracking (NMT) to detect native memory leaks.
Additionally, you can use tools like JConsole, JDK Mission Control, and native tools like pmap or PerfMon to monitor memory usage and detect memory leaks.
Would you like to know more about troubleshooting memory leaks or any specific topic mentioned above?
Wow! This response is indeed about troubleshooting Java memory leaks and is accurate!
The last sentence of the output asked if we would like to know more about any of the topics mentioned in the answer. To answer a follow-up question, the model needs to have access to the earlier questions and their corresponding responses. Let's see how we can achieve that by adding chat memory.
4. Add Chat Memory
We want the model to access the earlier questions and answers of the conversation so we can ask a follow-up question. Such functionality is possible by preserving the previous chain of questions and answers in chat memory. LangChain4j offers a few implementations of ChatMemory that you can use to remember conversations. OCI Generative AI also provides a mechanism to save the history of messages in a conversation, and we will use that as an example. As shown below, we will save the chat responses in a list of ChatChoice objects and use them later while creating a new chat request.
List<ChatChoice> chatMemory;
public void saveChatResponse(ChatResponse chatResponse) {
BaseChatResponse bcr = chatResponse.getChatResult().getChatResponse();
if (bcr instanceof GenericChatResponse resp) {
chatMemory = resp.getChoices();
}
}The chatbot can send these messages saved in the chat memory to the LLM along with our augmented prompt from the generateResponse() method.
public ChatResponse generateResponse(String prompt) {
...
Message message = UserMessage.builder()
.content(contents)
.build();
// messages below holds previous messages from the conversation
List<Message> messages = chatMemory == null ? new ArrayList<>() :
chatMemory.stream()
.map(ChatChoice::getMessage)
.collect(Collectors.toList());
// add the current query message to list of history messages.
messages.add(message);
GenericChatRequest genericChatRequest = GenericChatRequest.builder()
.messages(messages) // holds current message + history
...
...
...
// send chat request to the AI inference client and receive response
ChatResponse response = generativeAiInferenceClient.chat(request);
// save the response to the chat memory
saveChatResponse(response);Since we modified the project, let's clean and rebuild it with mvn clean verify. This command generates a new troubleshoot-assist-1.0.0.jar inside the target directory. Finally, launch the application using mvn exec:java -Dexec.mainClass=JavaTroubleshootingAssistant.
As we have chat memory enabled, let's ask a follow-up question to the previous answer.
question = "How do I enable NMT?"The output below shows that the response correctly provides guidance on enabling Native Memory Tracking (NMT) for troubleshooting native memory issues.
To enable Native Memory Tracking (NMT) in the HotSpot JVM, you can use the following command-line option:
`-XX:NativeMemoryTracking=[off|summary|detail]`
You can set the level of detail to either `summary` or `detail`, depending on the level of information you need. The `summary` level provides a high-level overview of native memory usage, while the `detail` level provides a more detailed breakdown of native memory usage.
For example, to enable NMT with the `summary` level, you can use the following command:
`java -XX:NativeMemoryTracking=summary -jar your_java_app.jar`
You can also enable NMT at runtime using the `jcmd` command:
`jcmd <pid> VM.native_memory summary`
Replace `<pid>` with the process ID of the Java process you want to enable NMT for.
Would you like to know more about using NMT to troubleshoot native memory leaks or how to interpret the NMT output?
And just like that, we have our simple Java Troubleshooting Assistant!
The complete example code we explored above can be found here: Java-Gen-AI
This article explored a few frameworks and libraries that are making tremendous contributions toward expanding the Java ecosystem to support AI integration. Frameworks like LangChain4j, Spring AI, and Jlama simplify integrating large language models into existing and new Java applications, enabling developers to assemble complex AI workflows. Even more, cloud-based generative AI services like Oracle Generative AI can scale further to build enterprise-level AI solutions. These developments position the Java language and platform as a key player in the AI-powered future of enterprise technology.