
Performance Improvements in JDK 25
Claes Redestad, Per-Ake Minborg on October 20, 2025In this article, we’ll take a walk through some of the many notable performance improvements and features in JDK 25. This is by no means exhaustive: JDK 25 comes with more than 3.200 issues fixed, of which almost a thousand were enhancements. About a hundred of these have been explicitly labeled as performance-related. We group the improvements into JDK Libraries, Garbage Collectors, Compiler, and Runtime, and list improvements in no particular order.
Enhancements in JDK Libraries
JEP 506: Scoped Values
The scoped values API was added as a preview feature in JDK 21 and has now been finalized in JDK 25.
Scoped values provide a novel mean to
pass implicit parameters to any method transitively called via a
ScopedValue. This may be used to improve performance and flexibility in
applications that use ThreadLocal to similar effects today, as it allows robust
and performant sharing of data across a large number of threads.
Instead of duplicating state per thread in an error-prone way, the new mechanism
allows shared access across any number of threads. This scales better because it has less memory overhead
(no per-thread copies) and lower synchronization cost. ScopedValues can be
especially beneficial when used in conjunction with virtual threads
and structured concurrency.
Structured concurrency was first previewed in JDK 21 and is still a preview API in JDK 25 (see JEP 505). Among the updates for JDK 25 is that the API now neatly handles scoped values such that child tasks inherit scoped values:
private static final ScopedValue<String> NAME = ScopedValue.newInstance();
ScopedValue.where(NAME, "duke").run(() -> {
try (var scope = StructuredTaskScope.open()) {
// each child task can retrieve "duke" from NAME
scope.fork(() -> childTask1());
scope.fork(() -> childTask2());
scope.fork(() -> childTask3());
scope.join();
..
}
});
Nicolai Parlog recently covered this feature and much more in his talk at Devoxx Belgium 2025, Structured Concurrency in Action
JDK-8354300 Mark String.hash field @Stable
In JDK 25, String was improved to make the String::hashCode function
constant foldable. This might lead to significant performance improvements in some common scenarios,
such as using String constants as keys in a constant, unmodifiable Map:
private static final Map<String, Foo> MAP = Map.of("constant", value, ...);
MAP.get("constant").foo();
In this scenario, constant folding means the JIT can skip the map lookup entirely, replacing the lookup with a direct call to value.foo() or better. In a targeted microbenchmark such as StringHashCodeStatic.nonZero
this brings us about an 8x speed-up.
In this article you can
read more about the benchmark and additional implementation details. In short,
the hash code for the string is now stored in a field that is marked with the
internal @Stable annotation. This allows the JIT compiler to trust and constant
fold the value if it is no longer the default zero value. While @Stable annotation is JDK-internal,
a general-purpose approach is on the way through the next feature of our article.
JEP 502: Stable Values (Preview)
Using the StableValue API (previewed in JDK 25), anyone can declare a lazy constant that is implicitly
stable, which means the JVM will treat it as a constant once a value has been lazily
computed. Computation is done using a computing function provided at declaration time, and the constant is
cached in a Supplier:
class OrderController {
private final Supplier<Logger> logger = StableValue.supplier(() -> Logger.create(OrderController.class));
void submitOrder(User user, List<Product> products) {
logger.get().info("order started");
...
logger.get().info("order submitted");
}
}
In the example above, the field logger is of type Supplier<Logger>, but,
at construction, no constant is yet initialized.
When we invoke logger.get() the first time, the underlying computing
function, () -> Logger.create(OrderController.class), is evaluated,
causing the constant to be initialized.
Once the constant is initialized, the JIT compiler can trust that the
constant will never change and is thus free to omit further
reads of the constant, i.e., constant folding. This technique can
provide significant performance improvements, including eliminating
code. Effectively, this has the same impact as the @Stable annotation
available in internal JDK code, but made available to library and application
developers in a safe and enforced manner.
It’s prudent to note that preview APIs are subject to change. At the time of
writing StableValue is set to be renamed to LazyConstant in JDK 26.
JDK-8345687 Improve the Implementation of SegmentFactories::allocateSegment
This Panama Foreign Function and Memory (FFM) enhancement speeds up allocating
native memory segments by up to 2x. This is achieved by explicitly aligning
memory, avoiding unnecessary merges and object allocation, improving zeroing,
and a few other tricks.
Better handling of shared memory in the java.lang.foreign component means
better performance when interoperating with native libraries. FFM was finalized
in JDK 22 with the delivery of JEP 454 and brings a promise of simplifying
native integration while outperforming JNI. Per has blogged about this in more
depth here.
JDK-8354674 AArch64: Intrinsify Unsafe::setMemory
This enhancement added an intrinsic to speed up Unsafe::setMemory, which is an API commonly used in I/O,
desktop and Foreign Function and Memory(FFM) APIs. The supplied microbenchmark showcases a ~2.5x speed-up when writing chunks of
data using java.lang.foreign.MemorySegment::fill.
Added Intrinsics for ML-KEM and ML-DSA API
JDK 24 added Quantum-Resistant Module-Lattice-Based Key Encapsulation Mechanism, or ML-KEM (JEP 496), and Quantum-Resistant Module-Lattice-Based Digital Signature Algorithm, or ML-DSA (JEP 497).
In JDK 25, the performance of many of these new APIs has doubled on AArch64 and Intel AVX-512 platforms thanks to specialized intrinsics. This puts the OpenJDK roughly on par with OpenSSL for many of these security operations on modern hardware.
- JDK-8349721 Add aarch64 intrinsics for ML-KEM
- JDK-8351412 Add AVX-512 intrinsics for ML-KEM
- JDK-8348561 Add aarch64 intrinsics for ML-DSA
- JDK-8351034 Add AVX-512 intrinsics for ML-DSA
JDK-8350748 VectorAPI: Method “checkMaskFromIndexSize” Should Be Force Inlined
In low-level libraries, fine-tuning how the JIT inlines can help ensure that some critical optimizations occur as expected. This enhancement addresses such an issue in the Vector API by forcing inlining to happen at a critical place, leading to a 14x speed-up on targeted benchmarks.
JDK-8350493 Improve Performance of Delayed Task Handling
The java.util.concurrent.ForkJoinPool was updated to implement ScheduledExecutorService to better deal with delayed tasks.
This major overhaul removes some locking-related bottlenecks and notably improves the performance of canceling delayed tasks (such as timeout handlers). Added some convenient methods such as submitWithTimeout too!
Other JDK Library Performance Enhancements and Bug Fixes
-
JDK-8356709 Avoid redundant
Stringformatting inBigDecimal.valueOf(double)Gives a 6-9x speed-up of
BigDecimal.valueOffor typical inputs. -
JDK-8353686 Optimize
Math.cbrtfor x86 64 bit platformsTogether with a follow-up fix (JDK-8358179) this x86 enhancement brings a 3x speed-up to Math.cbrt (cubic root). A similar change was attempted on AArch64 but failed to show any benefit there.
-
JDK-8357690 Add
@Stableandfinaltojava.lang.CharacterDataLatin1and otherCharacterDataclassesWhile currently unclear if this has any effects in the wild this could conceivably make some code constant foldable.
Garbage Collection Improvements
JEP 521 Generational Shenandoah
The generational mode of the Shenandoah garbage collector, introduced in JDK 24, has transitioned to a product feature in JDK 25.
JDK-8350441 ZGC: Overhaul Page Allocation
This major ZGC enhancement replaces the Page Cache in ZGC with a Mapped Cache, which improves how ZGC manages unused allocated memory. Implemented as a self-balancing binary search tree of contiguous memory ranges, the Mapped Cache merges memory ranges on insertion. Among other things, this reduces heap memory fragmentation. Another consequence of the overhaul is that ZGC no longer uses multi-mapped memory, which means that reported RSS usage will no longer look artificially inflated.
Joel Sikström has authored a comprehensive deep-dive about how ZGC allocates and manages memory with this large overhaul in focus here: How ZGC allocates memory for the Java heap.
JDK-8343782 G1: Use One G1CardSet Instance for Multiple Old Gen Regions
This one allows G1 to merge any old generation region’s remembered set with others, unlocking memory savings. On one GC stress test referenced in the PR, this reduces the peak memory used by remembered sets from 2Gb to 0.75Gb on a JVM with a 64GB heap. Or roughly 2% of the process total:
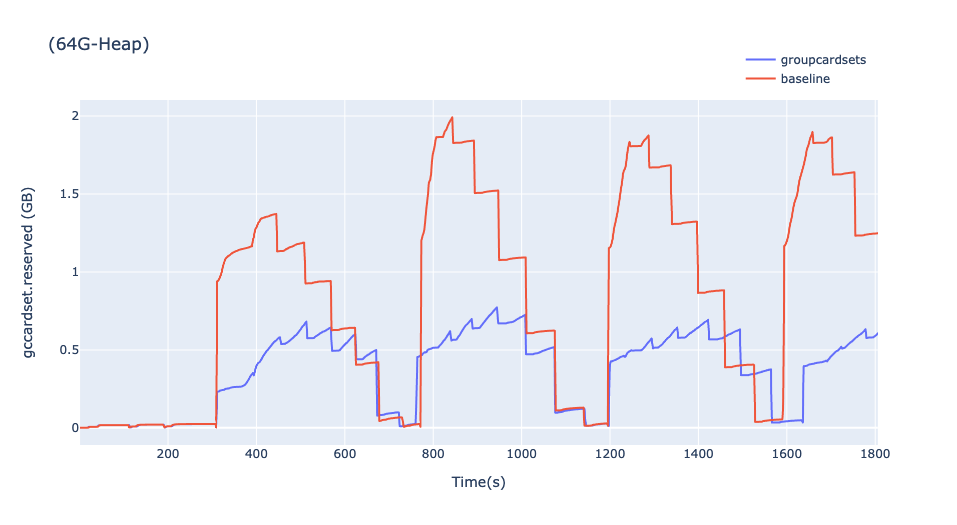
JDK-8351405 G1: Collection Set Early Pruning Causes Suboptimal Region Selection
G1 will now better estimate the cost of collecting regions during Mixed GCs and skip those that would significantly impact pause times. The result is reduced pause time spikes, particularly toward the end of a Mixed GC cycle, improving overall application performance. Thomas Schatzl has written in-depth about these and other GC changes on his blog: JDK 25 G1/Parallel/Serial GC changes.
JDK-8357443 ZGC: Optimize Old Page Iteration in Remap Remembered Phase
This enhancement leverages a pre-existing optimization to find all old pages without scanning the entire page table, speeding up significant collections when many pages don’t need to be considered for collection.
While likely a modest improvement on typical usage, this can lead to significant speed-ups in some corner cases,
such as when you manually trigger significant collections (e.g., using System.gc()) on large but relatively empty heaps.
The PR shows speed-ups of up to 20x on a 4GB heap, and up to 900x
on a 16TB heap for the worst-case setup.
Compiler Improvements
JDK-8343685 C2 SuperWord: Refactor VPointer with MemPointer
Part of a larger effort to improve auto-vectorization in C2. This is a technique where plain Java code is transformed by the JIT to use SIMD instructions, which can allow for large speed-ups.
This enhancement makes more patterns eligible for such optimization to great effect. In a recent talk at JVMLS, Emanuel Peter casually mentions how this snippet of code runs 33 times faster after this enhancement:
for (int i = 0; i < (int)a.byteSize(); i++) {
byte v = a.get(ValueLayout.JAVA_BYTE, i + invarL);
a.set(ValueLayout.JAVA_BYTE, i + invarL, (byte)(v + 1));
}
Emanuel has blogged extensively on auto-vectorization in the C2 compiler and this introduction might be a good starting point for a deep dive.
JDK-8307513 C2: Intrinsify Math.max(long,long) and Math.min(long,long)
This is another auto-vectorization improvement referenced in Emanuel’s Peter JVMLS talk. By giving some special treatment
to Math.max and Math.min, those operations can be considered for auto-vectorization by C2.
In a clipping variant (which combines both Math.min and Math.max) in the provided MinMaxVector
microbenchmark, we see 3-5x speed-ups on a range of platforms:
@Benchmark
public long[] longClippingRange(RangeState state) {
for (int i = 0; i < state.size; i++) {
state.resultLongs[i] = Math.min(Math.max(state.longs[i], state.lowestLong), state.highestLong);
}
return state.resultLongs;
}
Improving auto-vectorization allows clearly written, plain Java code to take advantage of SIMD capabilities on modern CPUs.
JDK-8347405 MergeStores with Reverse Bytes Order Value
In JDK 23, C2 was enhanced with a merge store optimization, which allows merging byte-by-byte stores into wider primitives in an efficient way. In JDK 25, this is further enhanced to enable such merges to happen also when bytes are stored in the reversed order. For example:
public void patchInt(int offset, int x) {
byte[] elems = this.elems;
elems[offset ] = (byte) (x >> 24);
elems[offset + 1] = (byte) (x >> 16);
elems[offset + 2] = (byte) (x >> 8);
elems[offset + 3] = (byte) x;
}
Focused microbenchmarks have seen up to a 4x speed-up on such code.
On typical little-endian systems, such as Intel x64 or Aarch64, this means Java may emit data in network order (big-endian) at significantly greater speed than before.
JDK-8346664 C2: Optimize Mask Check with Constant Offset
This enhancement improves mask checks such as ((index + offset) & mask) == 0 when offset is constant. This enables more constant folding of some relatively common low-level expressions.
While this was found and implemented to help specific Panama workloads, the optimization is generic and low-level.
Here’s a microbenchmark adapted from the one in the PR to avoid use of java.lang.foreign:
long address = 4711 << 3L;
@Benchmark
public void itsOver9000() {
for (long i = 0; i < 32768; ++i) {
if (((address + ((i + 1) << 3L)) & 7L) != 0) {
throw new IllegalArgumentException();
}
}
}
Since these expressions can now properly constant fold, the JIT goes above and beyond. It sees that the check will always be true and ends up optimizing away the entire loop. Result: 10,000x faster.
The fastest code will always be the code we don’t have to run at all!
Other Compiler Performance Enhancements and Bug Fixes
-
JDK-8353359 C2:
Or(I|L)Node::Idealis missingAddNode::IdealcallThis fixes a regression introduced in JDK 21 where expressions such as
(a | 3) | 6no longer constant folded as expected. -
JDK-8353041 NeverBranchNode causes incorrect block frequency calculation
Fixes an issue where performance of infinite loops could be adversely affected.
-
JDK-8317976 Optimize SIMD sort for AMD Zen 4
Makes sure AMD Zen 4 and later processors use appropriate optimized array sort routines.
-
JDK-8351414 C2: MergeStores must happen after RangeCheck smearing
Improves some cases where the aforementioned merge store optimization interacted poorly with another optimization by separating the optimization to a separate pass.
Runtime Improvements
JEP 515 Ahead-of-Time Method Profiling
Project Leyden aims to improve startup and warmup of Java applications while imposing as few limitations as possible. This is achieved by recording what an application is doing during a training run and saving that to an Ahead-of-Time cache for subsequent runs.
The AOT cache, introduced via JEP 483 in JDK 24, was extended in JDK 25 by JEP 515 to be able to collect method profiles during training runs. This enables the JVM to generate optimized native code immediately upon application startup, rather than having to wait for profiles to be collected. Hence, the warmup time is improved.
Some example programs start up 15-25% faster with this feature, compared to JDK 24 running a similarly trained application.
With this enhancement and JEP 514: Ahead-of-Time Command-Line Ergonomics delivered in JDK 25, Project Leyden is coming along nicely.
JEP 519: Compact Object Headers
Compact object headers were added as an experimental feature in JDK 24 and have now been promoted to a product feature.
When enabled with -XX:+UseCompactObjectHeaders, all objects on the heap shrink by 4 bytes, typically. This adds up to
substantial heap savings, and many benchmarks and real-world applications see significant speed-ups as a result due to
improved cache locality and reduced GC activity.
Users are strongly encouraged to try this out and provide feedback. We are considering turning it on by default in a future release.
Various Interpreter Improvements
- JDK-8356946 x86: Optimize Interpreter Profile Updates
- JDK-8357223 AAarch64: Optimize Interpreter Profile Updates
- JDK-8357434 x86: Simplify Interpreter::profile_taken_branch
Together, these improvements significantly enhance how the interpreter updates profile counters. During startup and warmup, the bytecode interpreter profiles which methods and branches are used, which informs the JVM on what to compile and how. The act of updating these counters can be noticeable during application startup and warmup.
In isolation, such optimizations are often lost in the noise, but over a release, they can and do add up. Going from JDK 24 to 25, the time to run a simple “Hello World!” has dropped from ~28.7ms to ~25.5ms in JDK 25. A neat 12% speed-up right off the bat.
While users of Project Leyden may unlock greater wins at scale, we think it’s great to see measurable improvements for free.
Other Runtime Performance Enhancements and Bug Fixes
-
JDK-8355646: Optimize ObjectMonitor::exit
This synchronization improvement allows us to immediately unpark waiting threads without releasing and reacquiring a lock. This reduces latency on some lightly contended locks.
-
JDK-8348402 PerfDataManager stalls shutdown for 1ms
Getting rid of a small sleep during JVM shutdown, for one. Good for all the short-running command line tools, build systems, etc.
-
JDK-8241678 Remove PerfData sampling via StatSampler
A nice cleanup removing a periodically running task
- JDK-8353273 Reduce number of oop map entries in instances
- JDK-8354560 Exponentially delay subsequent native thread creation in case of EAGAIN
-
JDK-8352075 Perf regression accessing fields
Fixes an issue from JDK 21 which could cause significant interpreter slowdowns on classes with many fields.
That’s All, Folks!
JDK 25 has been generally available for a while now, so don’t hesitate to try it out. If you would like to learn how JDK 25 compares to JDK 21 in terms of performance, we also recommend the session From JDK 21 to JDK 25 - Java Performance Update 2025 presented at Devoxx Belgium 2025.
As you test and migrate your applications, measure how your application performs on JDK 25 versus your current JDK. Did you notice anything that might have regressed? Get involved in the community and let us know! Join and raise an issue on the relevant mailing list.
We are already looking at a healthy set of improvements in the upcoming JDK 26 release and look forward to writing about those in some detail in spring 2026.
Until then… Stay on the fast path!